Google, Wolfram Alpha, and ChatGPT are all interactive tools that use a single-line text input field to provide textual results to users. While Google provides search results, a list of webpages and articles that will (hopefully) provide information related to the search queries, Wolfram Alpha provides answers related to mathematics and data analysis. ChatGPT, on the other hand, provides context-based answers.
The Power of Google, Wolfram Alpha, and ChatGPT
The power of Google lies in its ability to perform massive searches in databases and provide a series of matches. The power of Wolfram Alpha lies in its ability to analyze questions related to data and perform calculations based on those questions. The power of ChatGPT lies in its ability to analyze queries and produce detailed responses and results based on the most textually accessible information in the world.
The Two Main Phases of ChatGPT
ChatGPT has two main phases: pre-training and inference. Pre-training is the phase where data is collected, while inference is the phase where the user interacts with the ChatGPT.
Supervised and Unsupervised Pre-Training
Pre-training generally involves two main approaches: supervised and unsupervised. While supervised learning is the primary approach used in most AI projects, unsupervised pre-training is used in the most recent generation of generative AI systems like ChatGPT. In supervised learning, a model is trained on a set of labeled data, where each input is associated with a corresponding output. However, ChatGPT uses unsupervised pre-training, where a model is trained on data where no specific output is associated with each input. Instead, the model is trained to learn the underlying patterns and structures in the input data without any specific task in mind.
Transformer Architecture
The Transformer architecture is a type of neural network that processes natural language data. The Transformer processes word sequences using “self-attention” to evaluate the importance of different words in a sequence when making predictions. The network is made up of several layers, each with multiple sub-layers, including the self-attention layer and the feed-forward layer. During training, the model is updated based on the correspondence between the prediction and the actual output.
Training Data for ChatGPT
ChatGPT is based on the GPT-3 architecture, which was trained on a dataset called WebText2, a library of 45 terabytes of textual data. This immense amount of data allows ChatGPT to have tremendous knowledge on various topics.
Conclusion
ChatGPT is a powerful generative AI system that provides detailed responses based on the textually accessible information in the world. Its unsupervised pre-training and Transformer architecture have enabled it to learn and understand complex language patterns in a way that were previously inaccessible.
Source : www.zdnet.fr
➡️ Accéder à CHAT GPT en cliquant dessus


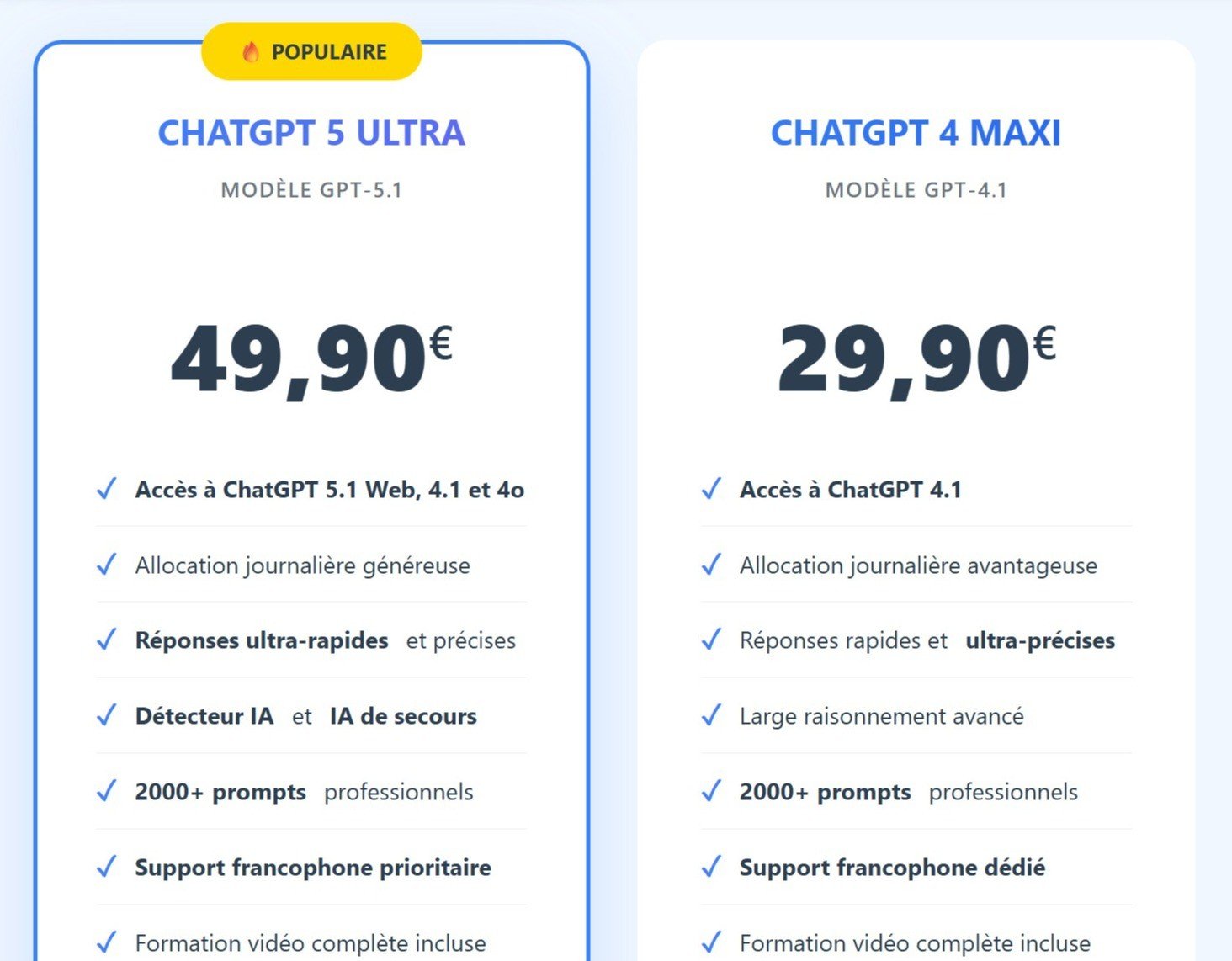
 Abonnez vous a Chat GPT
Abonnez vous a Chat GPT